Intelligenza artificiale per la generazione di render da schizzi
Qualità dei render generativi
Ad un occhio attento, i render sottostanti contengono delle imperfezioni e degli artefatti più o meno visibili. Anche la costruzione prospettica sembra avere qualche piccolo difetto. Ma se consideriamo che, nelle prime fasi di concept di un progetto, è spesso necessario dare una idea di massima dei volumi, degli ambienti, dei materiali e dello stile generale, è spesso possibile sacrificare la perfezione dei dettagli generati da una modellazione classica, i cui tempi di produzione hanno un ordine di grandezza in “ore” e “giorni” (soprattutto se è necessario produrre alternative e varianti), in favore di una generazione arificiale più veloce, i cui tempi di produzione hanno un ordine di grandezza in “minuti” (oltre ai tempi di “preparazione” degli schizzi ed il loro adattamento per essere digeriti dall’applicazione AI).

Render artificiale - variante 1

Render artificiale - variante 2

Render artificiale - variante 3

Render artificiale - variante 4
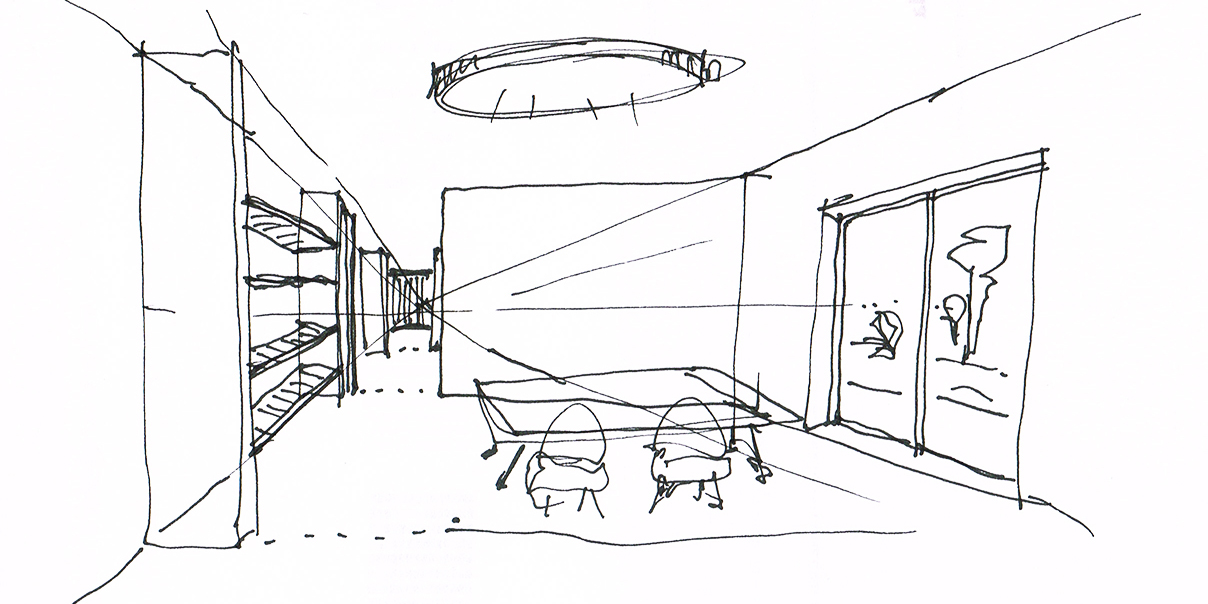
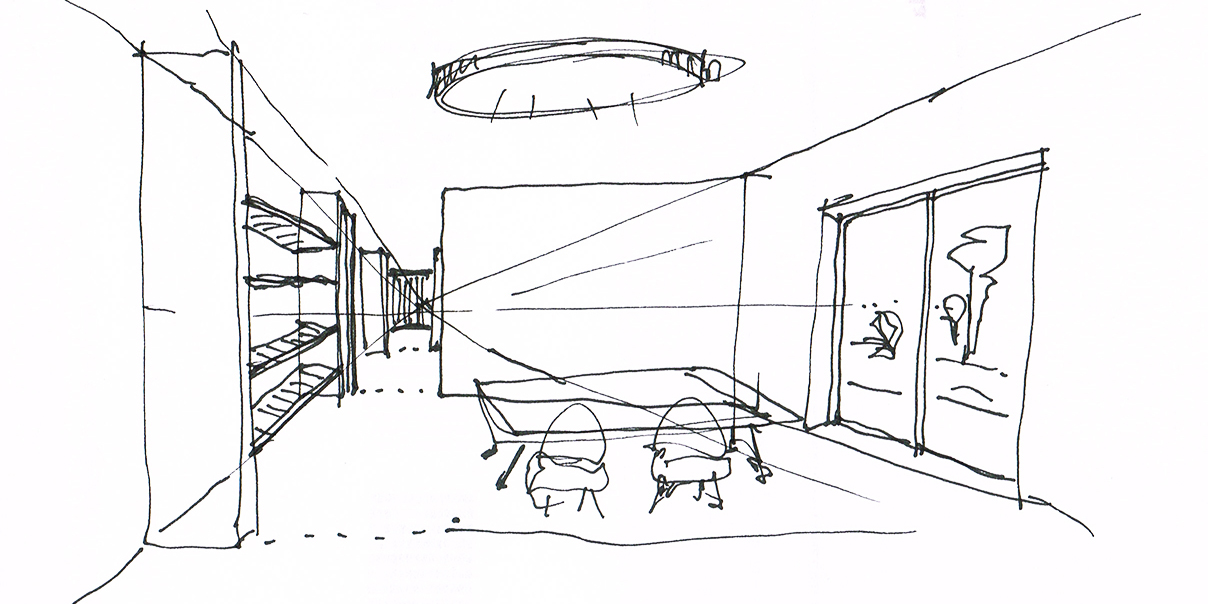
Schizzo di input originale

Segmentazione RGB
Le immagini sopra generate sono state prodotte in pochi minuti (per la parte di pura generazione) a partire da uno schizzo (non particolarmente preciso o dettagliato1), modificato manualmente applicando campiture RGB con codici specifici (anche in questo caso, in modo rapido), e applicando un algoritmo di segmentazione all’interno di un applicazione open-source che utilizza un modello LDM (Latent Diffusion Model), utilizzato localmente su una macchina con processore Nvidia. Aumentando la precisione dello schizzo e la qualità delle campiture RGB è possibile ottenere risultati migliori.
Le finiture, gli effetti di luce, i materiali, il colore del telaio dei serramenti, il tipo di ambiente esterno, e vari altri parametri edilizi, sono stati inseriti mediante descrittori testuali2 dei “desiderata”, scrivendo testualmente lo stile desiderato, e lasciando all’algoritmo di segmentazione il compito di riassociare il testo alle campiture RGB, e quindi al render finale. Ad esempio:
“raw photograph of interior house, with soft light, high detail, white walls, white neon lamp on the ceiling, round steel lamp, white ceiling, wooden shelves on the left, silver concrete floor, wooden table with steel legs, four red armchairs under the table, wooden shelves, clear windows, white frame windows, outdoor city in spring”.
Si può notare che il modello LDM non sempre traduce esattamente i descrittori testuali in associazioni corrette nel render. Ma considerando che il test, volutamente, si basa su uno schizzo molto rapido e su una segmentazione molto grezza, il risultato si può consierare sostanzialmente buono. Utilizzando uno schizzo più preciso e facenda una segmentazione migliore, le associazioni saranno molto più precise. Inoltre, è possibile rafforzare ogni singolo descrittore testuale con un peso diversificato, in modo che il LDM assegni un valore maggiore al descrittore per guidare la generazione verso il risultato atteso. E’ possibile anche usare descrittori testuali negativi per indicare al LDM di non includere nella sua generazione l’oggetto o lo stile indicato dal descrittore negativo; ad esempio, inserendo un descrittore negativo “books” il LDM non cercherà nel suo modello interno associazioni di dati che possano generare immagini di libri.
In realtà, i soli descrittori testuali non sono, da soli, sufficienti per ottenere questi render, soprattutto se è necessario vincolare la generazione artificiale ad uno schizzo specifico, e con materiali e finiture specifiche. Nelle applicazioni AI di generazione artificiale, usate localmente3, è necessario configurare svariati parametri ed è necessario preparare ed adattare i dati di input per permettere all’applicazione di utilizzare i dati (nel nostro caso, lo schizzo).
Infatti, ad esempio, se proviamo a semplificare la procedura scartando il metodo della segmentazione e delle campiture RGB, usando invece un metodo più rapido che fa uso di un modello di conversione dello schizzo in linee interpretabili dal LDM, otterremmo un risultato simile a questo:

Render artificiale algoritmo scribble - variante 1

Render artificiale algoritmo scribble - variante 2

Render artificiale algoritmo scribble - variante 3

Render artificiale algoritmo scribble - variante 4
Schizzo di input originale
Con questo metodo, il render generato mantiene solo la struttura dello schizzo, ovvero il LDM interpreta solo le linee, le prospettive, le componenti generiche e le posizioni degli elementi, e cerca di “riempire” le aree vuote con una “previsione” di ciò che queste aree possono contenere in base ai dati salvati in quello che viene definito il latent space 4 del modello LDM. Da un punto di vista progettuale, questo metodo può essere usato nelle fasi di brainstorming, per generare idee e visioni astratte dello spazio, in una sorta di “collage” creativo dal quale sviluppare il concept progettuale.
Applicazione di varianti ai render classici
Anche nel caso della modellazione classica, la generazione artificiale può essere usate per creare varianti dei render classici, ad esempio per inserire o modificare oggetti all’interno dei render. Nell’esempio sottostante, un render esistente è stato mappato in una zona (tecnica dell’inpainting) e sono stati inseriti descrittori testuali per ottenere, volta per volta, oggetti diversi nella posizione della scaffalatura originale. Nel caso delle mensole, i descrittori usati sono: “shelves, wood, pots, flowers”; nel caso della cucina: “kitchen”; nel caso dell’armadio: “white hard case, wardrobe”.

Render originale con maschera di inpainting

Render con inserimento artificiale di mensole

Render con inserimento artificiale di cucina

Render con inserimento artificiale di armadio
Non è tuttavia sufficiente l’utilizzo dei soli descrittori testuali. Per poter produrre una sosituzione di oggetti è necessario intervenire su altri parametri di controllo dei plugin integrativi5. Nella fattispecie, ControlNet è una delle integrazioni fondamentali per controllare la direzione dello sviluppo del render. Questa integrazione permette il controllo della sezione mascherata mediante controlli alternativi di posizione, di profondità di campo, di semplice referenza, e altri algoritmi simili. Altri parametri congiunti determinano i metodi di campionamento dal latent space, l’aderenza della generazione ai descrittori o ad altri parametri, e varie altre configurazioni minori.
Non è immediato trovare l’equilibrio di tutti i parametri, ma se si considera che il tempo dedicato alla mappatura della maschera, alle prove di renderizzazione e all’affinamento dei parametri, è durato una decina di minuti circa, è evidente la differenza di tempo rispetto alla modellazione e renderizzazione delle diverse varianti utilizzando la modellazione classica. Certamente, non si può guidare automaticamente il render verso una precisa e iper-realistica rappresentazione dei singoli dettagli desiderati o delle esatte finiture ed effetti di stile.
Per potersi avvicinare al dettaglio desiderato, è comunque possibile procedere in vari modi. Ad esempio, con ulteriori mascherature iterativamente su zone più piccole; oppure esportando il render e lavorandolo in un software di fotoritocco; oppure continuando a generare in continuo decine di ulteriori render fino a trovare il render più vicino alla soluzione desiderata. Questi approcci possono essere combinati insieme, per produrre velocemente delle soluzioni che si “avvicinano” al risultato desiderato, per poi perfezionarlo con altri metodi.
Modifica di texture e materiali di immagini esistenti
Per le applicazioni in cui sia necessario modificare texture e materiali in una immagine, ottenere un risultato qualitativamente utile è più complicato. Le procedure sono le medesime, ma è necessario spesso usare più integrazioni contemporanee (ad esempio usando più istanze di ControlNet per controllare la segmentazione, la profondità di campo, o i contorni).
Nel test seguente, il pavimento di colore nero è stato sostituito con un altro pavimento con finiture diverse.

Immagine di riferimento - fotografia reale

Render generativo - pavimento in cemento
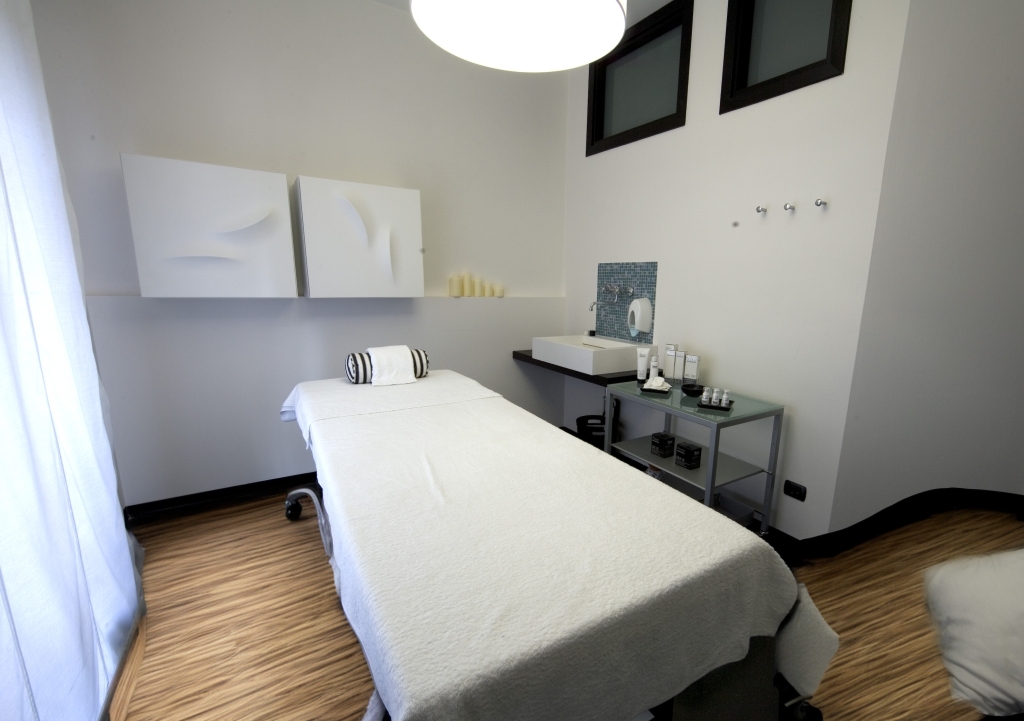
Render generativo - pavimento in legno 1

Render generativo - pavimento in legno 2
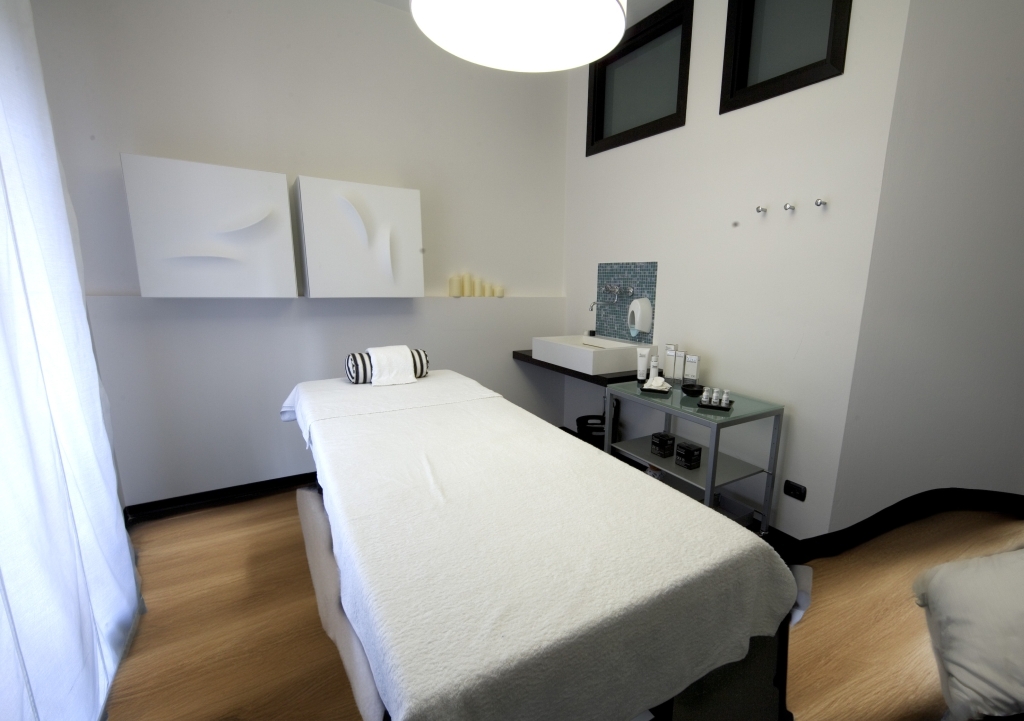
Render generativo - pavimento in legno 3

Segmentation mask

Depth mask
La modifica delle superfici richiede l’utilizzo di una maschera sulle superfici da modificare, e uno degli aspetti difficili da controllare è la generazione ai margini della maschera, dove il LDM fatica a ricostruire il contesto in presenza di zone scure e con poco contrasto, o di margini non ben definiti. Uno dei metodi di preparazione delle immagini di input, infatti, è quello di aumentare il contrasto e la luminosità per agevolare il LDM al riconoscimento dei margini, dei confini e delle aree.
Oppure, è possibile integrare un ulteriore integrazione ControlNet in modalità “canny” per vincolare i contorni degli oggetti, ed imporre al LDM le sagome interne all’immagine. Nel render seguente è possibile vedere come gli artefatti presenti nel test precedente (tra il margine del pavimento e gli altri oggetti della scena) siano stati mitigati, anche se non del tutto scomparsi. Ma si nota come il telo sul lettino e il cuscino sulla destra abbiano mantenuto sostanzialmente la stessa struttura e forma dell’immagine originale, senza essere modificati sui bordi dal LDM durante la modifica del pavimento.
Render generativo con integrazione ControlNet in modalità “canny”
Un altro aspetto difficile da controllare è la dimensione e i rapporti proporzionali tra la texture e il contesto. Diversamente dall’UV mapping della modellazione 3D classica, non è possibile definire scala, orientamento e traslazioni della texture. Il LDM cerca di generare una texture in base ai descrittori testuali e in base all’immagine sottostante, quindi non è possibile ancora indirizzare con precisione la generazione desiderata.
A seconda del tipo di immagine e del tipo di texture da modificare, può essere più efficace modificare le texture usando il fotoritocco classico. Tuttavia, una volta trovata la configurazione adatta dei parametri, è possibile generare molte varianti in poco tempo. Inoltre, non sempre è necessario ottenere una precisione elevata, soprattutto in fase di concept o qualora sia necessario proporre velocemente varie opzioni ad altri soggetti coinvolti nel progetto.
Risoluzione dei render
Uno degli aspetti particolari della generazione artificiale è la risoluzione delle immagini. Diversamente dalla renderizzazione classica, nella quale si definisce a priori la risoluzione desiderata del render, nell’ambito del LDM la risoluzione è legata alla risoluzione di apprendimento originale delle immagini da parte del modello usato. I recenti modelli LDMs sono addestrati su dataset di milioni di immagini6, campionati su una risoluzione finale di 512 x 512 pixel, oppure di 768 x 768 pixel.
Quindi, al momento della generazione del render, è in genere necessario utilizzare queste risoluzioni di partenza, o comunque risoluzioni vicine. Per ottenere risoluzioni più elevate sono disponibili dei metodi integrati, che fanno uso di algoritmi di ingrandimento, detti di upscaling. In sostanza, l’immagine generata viene processata nuovamente per inserire generativamente e “intelligentemente” ulteriori pixel.
Questi algoritmi non sono analoghi al resampling che si usa nel fotoritocco, ma è una vera e propria rielaborazione fatta dalla rete neurale del modello LDM per integrare i pixel necessari all’ingrandimento. I vari algoritmi di upscaling hanno, a loro volta, ulteriori parametri di configurazione per guidare l’ingrandimento dell’immagine.
I render in questa pagina sono stati generati con una risoluzione di 1024 x 512 pixel (o di 1024 x 721 pixel nel caso del test sul pavimento), e non sono stati ulteriormente ingranditi. Ma è possibile aumentarne la risoluzione con un fattore moltiplicativo (ad esempio x2), usando gli algoritmi di upscaling, per ottenere immagini più grandi (ad esempio 2048 x 1024 pixel). Con ulteriori passaggi si possono ottenere risoluzioni maggiori. Nuovi modelli LDMs sono in fase di addestramento su immagini con risoluzione nativa maggiore, quindi in futuro aumenterà la qualità del dettaglio generato7.
Casualità e controllo della generazione
A prima vista, utilizzare questi processi appare complicato. Ma il vantaggio del metodo di generazione degli LDMs è la possibilità di generare molte varianti dei render semplicemente modificando i descrittori testuali nel “prompt”, per guidare la generazione verso il risultato desiderato. Inoltre, una volta impostate le configurazioni di base, avendo molti schizzi, è possibile generare render di tutti gli schizzi necessari in poco tempo (se paragonato alle procedure classiche di renderizzazione).
Il vantaggio deterministico e iper-realistico della classica modellazione 3D può essere superato dalla enorme quantità di varianti che è possibile generate con gli LDMs, i quali operano con un processo stocastico8 ( Citation: Croitoru, Hondru & al., 2023 Croitoru, F., Hondru, V., Ionescu, R. & Shah, M. (2023). Diffusion models in vision: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9). 10850–10869. https://doi.org/10.1109/tpami.2023.3261988 ) . La generazione artificiale può apparire come un processo “casuale”, ma in realtà sono processi guidati che fanno uso di tecniche di text conditioning ( Citation: Radford, Kim & al., 2021 Radford, A., Kim, J., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G. & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. CoRR, abs/2103.00020. [i18n] apa_retrieved_from https://arxiv.org/abs/2103.00020 ) e di classifier guidance ( Citation: Dhariwal & Nichol, 2021 Dhariwal, P. & Nichol, A. (2021). Diffusion models beat GANs on image synthesis. CoRR, abs/2105.05233. [i18n] apa_retrieved_from https://arxiv.org/abs/2105.05233 ; Citation: Ho & Salimans, 2022 Ho, J. & Salimans, T. (2022). Classifier-free diffusion guidance. [i18n] apa_retrieved_from https://arxiv.org/abs/2207.12598 ) per orientare la generazione di immagini verso il più probabile risultato desiderato.
I modelli attuali presentano ancora sfide e questioni da risolvere ( Citation: Zhang, Wang & al., 2023 Zhang, T., Wang, Z., Huang, J., Tasnim, M. & Shi, W. (2023). A survey of diffusion based image generation models: Issues and their solutions. [i18n] apa_retrieved_from https://arxiv.org/abs/2308.13142 ) , ma gli sviluppi in questo campo sono molto rapidi. I problemi e la “casualità” correlate al metodo di generazione saranno sempre più sotto controllo. Già oggi esistono molte integrazioni open-source che permettono di vincolare diversi tipi di output, come ad esempio la possibilità di inserire persone nelle immagini in pose arbitrarie, usando la libreria e i metodi OpenPose ( Citation: Cao, Hidalgo & al., 2018 Cao, Z., Hidalgo, G., Simon, T., Wei, S. & Sheikh, Y. (2018). OpenPose: Realtime multi-person 2D pose estimation using part affinity fields. CoRR, abs/1812.08008. [i18n] apa_retrieved_from http://arxiv.org/abs/1812.08008 ; Citation: Wei, Ramakrishna & al., 2016 Wei, S., Ramakrishna, V., Kanade, T. & Sheikh, Y. (2016). Convolutional pose machines. CoRR, abs/1602.00134. [i18n] apa_retrieved_from http://arxiv.org/abs/1602.00134 ) ; il già citato ControlNet con vari modelli di controllo ( Citation: Zhang, Rao & al., 2023 Zhang, L., Rao, A. & Agrawala, M. (2023). Adding conditional control to text-to-image diffusion models. [i18n] apa_retrieved_from https://arxiv.org/abs/2302.05543 ) ; tecniche di fine tuting che permettono di personalizzare i modelli LDMs con proprie immagini, come DreamBooth ( Citation: Ruiz, Li & al., 2023 Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M. & Aberman, K. (2023). DreamBooth: Fine tuning text-to-image diffusion models for subject-driven generation. [i18n] apa_retrieved_from https://arxiv.org/abs/2208.12242 ) ; e altre integrazioni che permettono di controllare generazioni multiple in zone diverse dell’immagine.
La generazione artificiale delle immagini
Il modelli di diffusione per la generazione artificiale delle immagini nacquero per risolvere problemi in ambito di machine learning, in particolare per creare modelli di insiemi di dati complessi, utilizzando famiglie di distribuzione di probabilità, per i quali fosse possibile trattare analiticamente o computazionalmente gli aspetti di apprendimento (learning), di campionamento (sampling), di inferenza (inference) e di valutazione (evaluation) ( Citation: Sohl-Dickstein, Weiss & al., 2015 Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N. & Ganguli, S. (2015). Deep unsupervised learning using nonequilibrium thermodynamics. CoRR, abs/1503.03585. [i18n] apa_retrieved_from http://arxiv.org/abs/1503.03585 ) .
Nel 2015 furono introdotti i primi modelli di diffusione probabilistica, che erano capaci di generare una distribuzione di punti (data distribution) invertendo il processo con il quale avevano in precedenza trasformato la distribuzione in “rumore gaussiano” (noise). In sostanza, una “immagine” 9 viene progressivamente degenerata aggiungendo rumore (con una distribuzione gaussiana) fino a quando l’immagine non è più riconoscibile. Successivamente, il modello riesce a rigenerare l’immagine originale a partire dal rumore gaussiano.
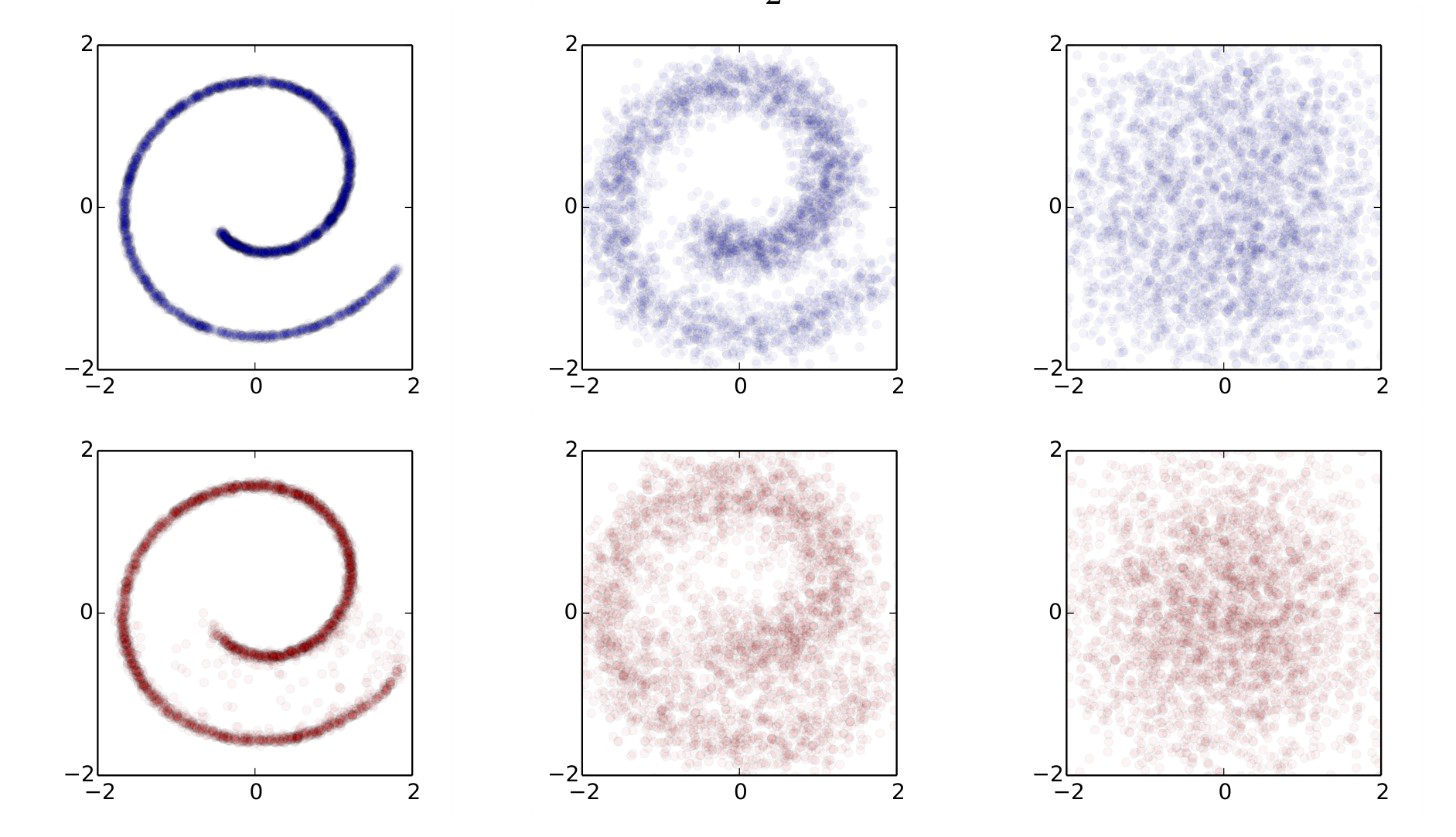
Diffusione gaussiana (in alto, da leggere da sinistra a destra) e processo inverso di diffusione gaussiana (in basso, da leggere da destra a sinistra)
Nella prima fila blu, l’immagine di sinistra (un “data distribution” in forma di spirale) subisce una diffusione gaussiana, in molteplici passaggi, fino a trasformarsi in rumore gaussiano a destra. Nella seconda fila rossa, da leggere da destra a sinistra, il rumore gaussiano a destra viene diffuso inversamente, in molteplici passaggi, per generare l’immagine a sinistra, mediante analisi della media gaussiana e della covarianza ( Citation: Sohl-Dickstein, Weiss & al., 2015 Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N. & Ganguli, S. (2015). Deep unsupervised learning using nonequilibrium thermodynamics. CoRR, abs/1503.03585. [i18n] apa_retrieved_from http://arxiv.org/abs/1503.03585 ) .
In seguito, ulteriori studi hanno trovato il modo di semplificare i modelli di diffusione probabilistica attraverso correlazioni con metodi di denoising score matching 10, ma questi modelli risentivano dell’alto numero di sample (campionamenti) necessari per la diffusione dal modello ( Citation: Ho, Jain & al., 2020 Ho, J., Jain, A. & Abbeel, P. (2020). Denoising diffusion probabilistic models. CoRR, abs/2006.11239. [i18n] apa_retrieved_from https://arxiv.org/abs/2006.11239 ) .
Nel 2021, un altro paper fondamentale, ha mostrato come sia possibile apportare ottimizzazioni e modifiche agli algoritmi precedenti, riducendo il numero di passaggi necessari per il sampling, ottenendo comunque campioni di alta qualità ( Citation: Nichol & Dhariwal, 2021 Nichol, A. & Dhariwal, P. (2021). Improved denoising diffusion probabilistic models. CoRR, abs/2102.09672. [i18n] apa_retrieved_from https://arxiv.org/abs/2102.09672 ) .
Questi studi sui modelli di diffusione probabilistica hanno dato il via ad una enorme mole di ricerche e studi ( Citation: diff-usion, 2020 diff-usion (2020). Awesome-diffusion-models. GitHub. [i18n] apa_retrieved_from https://github.com/diff-usion/Awesome-Diffusion-Models ) , ed ha portato la generazione artificiale delle immagini in ambito prosumer. L’utilizzo di queste tecnologie non è ancora ampiamente accessibile al mercato consumer, dato che uno dei limiti è l’hardware necessario per poter utilizzare gli applicativi necessari. In particolare, sono necessarie schede video con processori GPU con compilazione CUDA, con un’alta quantità di VRAM (almeno 24GB, per poter gestire modelli più grandi e per poter generare immagini ad una risoluzione il più alta possibile) e con una classe di processore il più avanzata possibile (per ridurre i tempi di generazione delle immagini).
Bibliografia
- Croitoru, Hondru, Ionescu & Shah (2023)
- Croitoru, F., Hondru, V., Ionescu, R. & Shah, M. (2023). Diffusion models in vision: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9). 10850–10869. https://doi.org/10.1109/tpami.2023.3261988
- Sohl-Dickstein, Weiss, Maheswaranathan & Ganguli (2015)
- Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N. & Ganguli, S. (2015). Deep unsupervised learning using nonequilibrium thermodynamics. CoRR, abs/1503.03585. [i18n] apa_retrieved_from http://arxiv.org/abs/1503.03585
- Wei, Ramakrishna, Kanade & Sheikh (2016)
- Wei, S., Ramakrishna, V., Kanade, T. & Sheikh, Y. (2016). Convolutional pose machines. CoRR, abs/1602.00134. [i18n] apa_retrieved_from http://arxiv.org/abs/1602.00134
- Cao, Hidalgo, Simon, Wei & Sheikh (2018)
- Cao, Z., Hidalgo, G., Simon, T., Wei, S. & Sheikh, Y. (2018). OpenPose: Realtime multi-person 2D pose estimation using part affinity fields. CoRR, abs/1812.08008. [i18n] apa_retrieved_from http://arxiv.org/abs/1812.08008
- Ho, Jain & Abbeel (2020)
- Ho, J., Jain, A. & Abbeel, P. (2020). Denoising diffusion probabilistic models. CoRR, abs/2006.11239. [i18n] apa_retrieved_from https://arxiv.org/abs/2006.11239
- Nichol & Dhariwal (2021)
- Nichol, A. & Dhariwal, P. (2021). Improved denoising diffusion probabilistic models. CoRR, abs/2102.09672. [i18n] apa_retrieved_from https://arxiv.org/abs/2102.09672
- Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger & Sutskever (2021)
- Radford, A., Kim, J., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G. & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. CoRR, abs/2103.00020. [i18n] apa_retrieved_from https://arxiv.org/abs/2103.00020
- Dhariwal & Nichol (2021)
- Dhariwal, P. & Nichol, A. (2021). Diffusion models beat GANs on image synthesis. CoRR, abs/2105.05233. [i18n] apa_retrieved_from https://arxiv.org/abs/2105.05233
- diff-usion (2020)
- diff-usion (2020). Awesome-diffusion-models. GitHub. [i18n] apa_retrieved_from https://github.com/diff-usion/Awesome-Diffusion-Models
- Ho & Salimans (2022)
- Ho, J. & Salimans, T. (2022). Classifier-free diffusion guidance. [i18n] apa_retrieved_from https://arxiv.org/abs/2207.12598
- Ruiz, Li, Jampani, Pritch, Rubinstein & Aberman (2023)
- Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M. & Aberman, K. (2023). DreamBooth: Fine tuning text-to-image diffusion models for subject-driven generation. [i18n] apa_retrieved_from https://arxiv.org/abs/2208.12242
- Zhang, Rao & Agrawala (2023)
- Zhang, L., Rao, A. & Agrawala, M. (2023). Adding conditional control to text-to-image diffusion models. [i18n] apa_retrieved_from https://arxiv.org/abs/2302.05543
- Zhang, Wang, Huang, Tasnim & Shi (2023)
- Zhang, T., Wang, Z., Huang, J., Tasnim, M. & Shi, W. (2023). A survey of diffusion based image generation models: Issues and their solutions. [i18n] apa_retrieved_from https://arxiv.org/abs/2308.13142
Citazione articolo
Per citare questo articolo, usate il seguente codice:
@article {bonfanti2023diffusionrender,
author = {André Bonfanti},
title = {{Intelligenza artificiale per la generazione di render da schizzi}},
journal = {Form Follow Science - ISSN 2499-8524},
year = 2023,
month = September,
url = "https://studio.andrebonfanti.it/intelligenza-artificiale-generazione-render-da-schizzi/",
note = {Last modified: 2023.09.09}
}
-
Questo è importante, perché ad una maggiore precisione dei dati di input corrisponde una migliore generazione e precisione delle immagini. Ai fini di questo test, lo schizzo utilizzato è stato disegnato in pochi secondi e volutamente grezzo, per valutare la capacità interpretativa dei LDMs. ↩︎
-
Il termine inglese corretto è prompt, la cui traduzione italiana sarebbe “suggerimento” o “richiesta”. Ma la traduzione letterale non rende il meccanismo di funzionamento delle parole, per cui uso il termine descrittori testuali. ↩︎
-
Con “localmente” si intende l’uso delle applicazioni sul proprio PC. Diversamente dalle applicazioni di AI disponibili online, alle quali ci si può connettere per utilizzare alcune delle funzionalità dei modelli LDMs, le applicazioni locali permettono di utilizzare e controllare molti più parametri e metodi di generazione. Inoltre, le applicazioni locali garantiscono la privacy dei dati e un flusso di lavoro più strutturato. ↩︎
-
Il latent space è una rappresentazione del mondo sottoforma di dati compressi e salvati in un modello LDM insieme ad altri parametri e configurazioni. Semplificando, è una rappresentazione di immagini preesistenti codificate vettorialmente in un file LDM. ↩︎
-
Tecnicamente, per ottenere questi render, oltre ad avere installato localmente tutti gli applicativi, è necessario definire e impostare molti aspetti:
- le configurazioni di base dei software;
- la scelta dei modelli di diffusione (“checkpoint”);
- le configurazioni sui parametri di generazione (“sampling”);
- la segmentazione dello schizzo in aree codificate;
- i parametri di riconoscimento dello schizzo;
- la descrizione testuale (“positive prompt” e “negative prompt”);
- i metodi di “upscaling” per aumentare la risoluzione delle immagini generate;
- e altri parametri. Inoltre, anche se non strettamente necessario, è molto utile conoscere i meccanismi di funzionamento dei modelli LDMs e i principi generali che li governano.
-
Esistono vari modelli addestrati con diverse quantità di immagini. Ad esempio, Stable Diffusion è stato addestrato su 600 milioni di coppie immagini-didascalie a partire dal dataset LAION-5B. Alla pagina LAION-Aesthetics è possibile consultare i diversi sotto-modelli esistenti per il dataset di LAION-5B, e alla pagina laion-aesthetic-6pls è possibile vedere un sottoinsieme (12 milioni di immagini) del dataset usato da Stable Diffusion (grazie al lavoro fattoda Andy Baio e Simon Willison). ↩︎
-
Alla data di questo articolo, ad esempio, il modello Stable Diffusion XL è stato addestrato su immagini a 1024 x 1024 pixel, quindi stiamo già assistendo ad un processo di miglioramento dei modelli. ↩︎
-
In ambito di machine learning, e in particolare della generazione artificiale delle immagini, si deve parlare più propriamente di metodi deterministici o probabilistici degli algoritmi matematici utilizzati per “predire” il risultato a partire dai dati di input. In ambito LDMs si utilizzano metodi probabilistici i quali, attraverso le reti neurali, generano immagini a partire dal cosiddetto latent space, ovvero una rappresentazione del mondo sottoforma di dati compressi, i quali sono salvati nel modello LDM insieme ad altri parametri e configurazioni. ↩︎
-
Non è corretto parlare di “immagine”. Il termine corretto è “distribuzione di dati”. Nel paper del 2015, la figura qui riportata non è una immagine in senso classico ma è, appunto, una distribuzione di punti in un piano 2D. Ma per semplificare il concetto, uso il termine “immagine” per fornire una intuizione immediata dei concetti. ↩︎
-
Il denoising score matching è assimilabile ad una tecnica intelligente che permette di “pulire” i dati disordinati misurando quanto probabili siano diversi pattern e cercando la migliore corrispondenza per la versione pulita e chiara dei dati. ↩︎